Where are all the trillion dollar biotechs?
Of the many trends people chase in biotech, the only one that proves sure and consistent is declining returns. Even after adjusting for inflation, the number of new drugs approved per $1 billion of R&D spending has halved approximately every nine years since 1950. Deloitte's forecast R&D IRR for the top 20 pharmas fell below the industry's cost of capital (~7-8%) between 2019 and 2022. In other words, while the industry remained profitable overall, the incremental economics of R&D investment were value-eroding rather than value-creating. So, while other industries have a reason to treat the current market downturn as transient, the business of developing medicine has a more fundamental problem to deal with - it is quite literally shrinking out of existence.
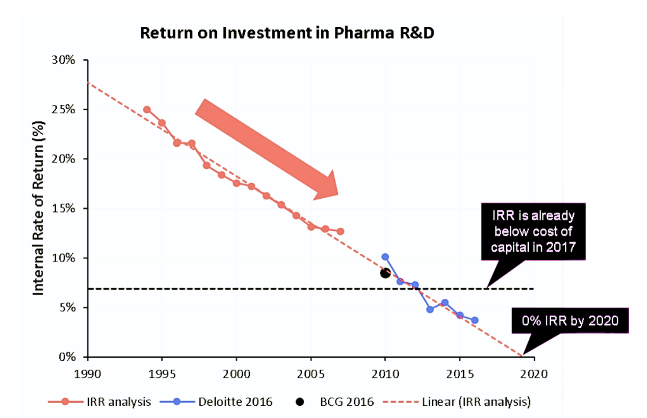
Pharma would need multiple $20 billion-per-year outcomes to reverse this trend, yet only three in history - Humira, Keytruda, and Pfizer's COVID vaccine - have ever reached that scale. This leads to the thought experiment motivating this essay: why haven't our best current strategies produced a trillion-dollar biotech, and can we ever get there? Here, I focus on the mental models I saw others lean on to "get biotech off hard mode." Human genetics, drug repurposing, and AI are the most common levers, and each promises to cut costs or derisk pipelines. But the more you look into specific companies and their stories, the more you notice that these strategies rarely work. This is especially true once you turn to age-related diseases, the only market large enough to rescue pharma's economics, yet the one where our best heuristics work the least.
[1] Tirzepatide and Semaglutide are projected to get there soon. Dupixent and Skyrizi are projected to get there over the next few years.
Decreasing the R&D investment required to develop new drugs
Can genetic targets create trillion-dollar value?
Accounting for failed candidates and capital costs, the industry average to bring one new drug to market is famously just over $2 billion. To improve those odds, developers for years have searched for features that distinguish winners from failures. Among the various predictors tested - animal models, pathway plausibility, chemical novelty - having human genetics back up the mechanism has emerged as one of the strongest success multipliers.
If loss or gain of function in a gene is strongly linked to a certain phenotype in humans, it's reasonable to assume that you can achieve said phenotype by inhibiting that gene with a drug. This has been confirmed in 2 major studies published in the past decade, Nelson et al., 2015 & King et al., 2019, showing that the approval odds ratio for drugs targeting proteins with strong genetic linkage to disease is at least double (OR = 2.1).
'Strongly linked' here is key - not all genetic evidence is created equal. Mendelian variants - very rare in the population but with high-penetrance (the probability that someone with a variant would have a disease) - have the clearest boost to translational success rate. With some notable exceptions, Mendelian variants overwhelmingly describe rare disorders (prevalence typically <1 in 2,000). The majority of the genetic variants are not rare though, typically published in GWAS studies, and tend to have a small effect size (low penetrance). According to the same studies, these low-to-medium penetrance GWAS variants tend to have little to no effect on approval rates. This leaves drug developers relying on genetic targets with a tough tradeoff: small populations with high-confidence targets, or big populations with low-to-medium confidence targets, with rare exceptions in between.
Rare disease focus doesn't necessarily rule out blockbuster outcomes. Spinal muscular atrophy has fewer than 35,000 patients globally, but SMA drugs (Spinraza, Zolgensma, Risdiplam) collectively generated more than $4.5 billion in global sales in 2023. The same is true for a few other rare indications - cystic fibrosis ($9.87 billion global sales in 2023, with only 100,000 patients globally) and hemophilia A ($10.29 billion in 2023, 652,000 patients). Does it mean that you can build an extremely valuable (both for patients and commercially) biotech company by focusing solely on high-confidence rare targets? Not quite! The story shows over and over again that you can approve therapies for rare life-threatening disorders, and still fail as a company. After spending 33 years in development and trials and approving 3 drugs, Bluebird Bio was recently acquired for a mere $30 million. Amsterdam Molecular Therapeutics was liquidated less than a year after approving the first gene therapy for lipoprotein lipase deficiency. Orchard Therapeutics won approvals for metachromatic leukodystrophy, but annual sales never rose above a few tens of millions, forcing a sale at a fraction of their peak valuation. Eiger filed for Chapter 11 bankruptcy while having an approved drug for progeria. Of the companies that are active in the rare disease space, Sarepta, BioMarin, and Ultragenyx have approved multiple drugs over the years, but are currently suffering in the excruciating bloodbath of public markets. With the Inflation Reduction Act cutting orphan drug credits, it will only get worse.

In the long term, the commercial successes seen in SMA, Hemophilia, and cystic fibrosis are likely to be an exception rather than the rule. That's because the majority of variants with high penetrance (=high confidence in gene-disease linkage) are diseases with extremely low prevalence or diseases with lower unmet need (where phenotypes are not as severe). Under the current model of multi-year capital-intensive and multi-stage trials, development budgets for these diseases easily exceed peak sales, making it hard to build a commercially successful company focusing on very small patient populations. Even if the 'biological failure rate' is lower due to genetics. And even if you approve multiple drugs.
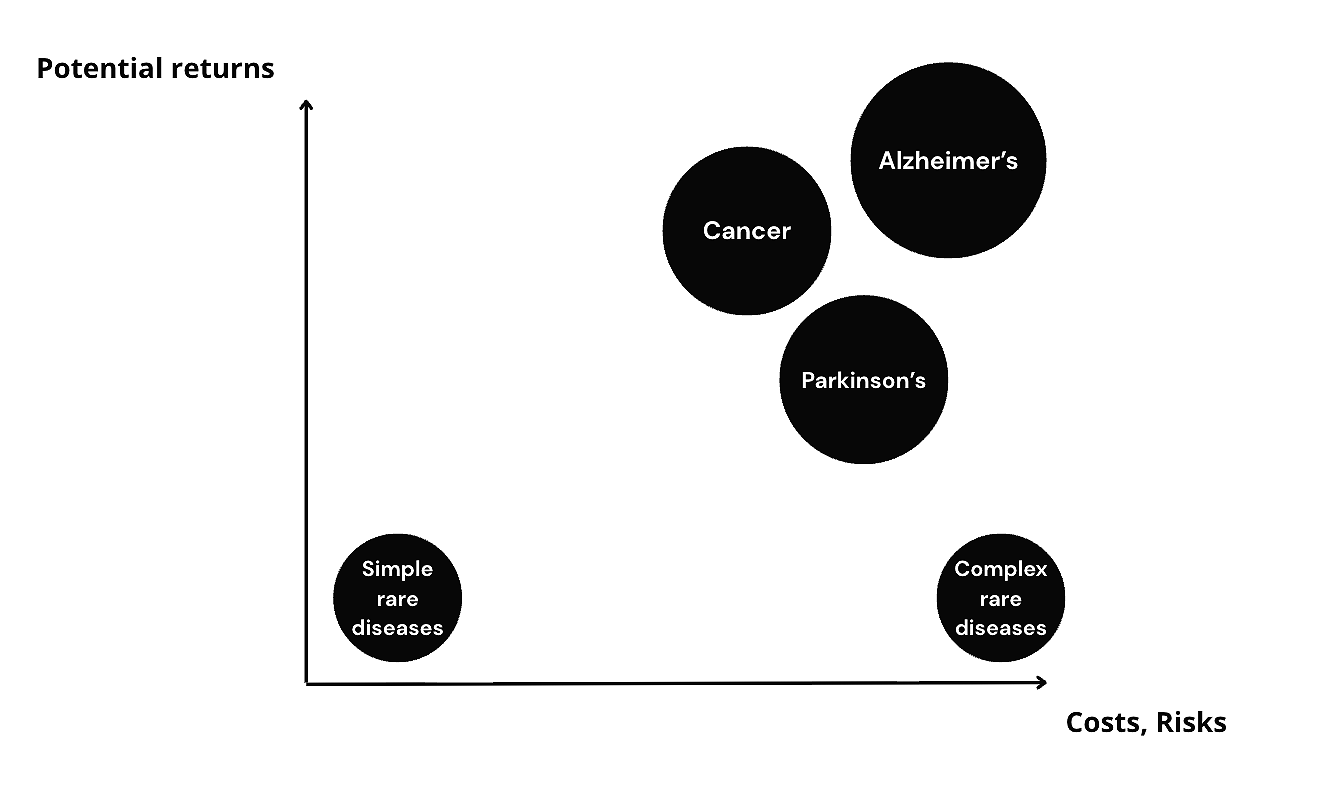
There are some broader exceptions to genetic target success, too. According to the Nelson / King studies I mentioned, genetic variants seemed to have no impact on success rate in oncology or CNS indications. Genetic CNS targets like BACE1 & MAPT (Alzheimer's), alpha-synuclein (Parkinson's), HTT (Huntington), and Nav1.7 (pain) are all pharma's darlings that left a graveyard of assets behind.
There are also plenty of examples of selecting a genetically validated target, often outside of oncology or CNS, and failing over and over again to deliver on the promise. CETP variant was enriched in centenarian cohorts and showed coronary heart disease reduction in people with the variant, yet 4 different drugs failed in early-stage trials (likely asset-specific failure). MSTN inhibition leads to obvious muscle mass gains, yet there were 4 failed MSTN antibodies before Scholar Rock got apitegromab approved earlier this year (indication/trial design failure). The list goes on and on.
Genetic targets have led to quite a few valuable drugs and a few good companies, but only 4 of the top 20 best-selling drug classes had a target with a strong genetic linkage before the drug was launched. It is also true that most age-related diseases are unlikely to be solved through genetic targets. In other words, one of the biggest levers you have for target selection can barely be applied in some of the biggest markets.
Some big companies focused on genetic targets that I think are worth building:
Trying to identify rare genetic variants for high-prevalence indications. This will likely be a tough hunt, but the majority of African, Caribbean, and Indigenous genomes are currently unsequenced, so there are plenty of places we can be looking!
There are some extremely great proposals out there for how to make rare disease cures financially feasible. For many of the CRISPR workflows, the components are highly reusable and standardized - mRNA for the editor, LNP components, and so on. You can even reuse your manufacturing workflow (which is one of the most expensive components for initiating Phase 1 trials). To date, most CRISPR companies have focused on playing within existing regulatory frameworks, dedicating most of their time to polishing the technology they have. But I think we are long past the point of being ready to build a 'Loyal for rare disease'. By that I mean - focus on doing the regulatory heavy lifting of implementing n=1 trials and be the first person to benefit from it.
There are at least several precedents for n=1 trials in the US: baby KJ that received a personalized CRISPR treatment early 2025, and Parkinson's patient that self-funded a dopaminergic neuron therapy at Mass General back in 2022. There is also the n-Lorem foundation that filed 15 INDs in the past 5 years for ultra-rare diseases. I think it's a big loss that in the US, companies are not allowed to profit from n=1 compassionate use trials. But other countries, like Japan, do allow this as a profitable business model.
I mentioned that CNS indications are the only area where genetic target selection seems not to have any impact on approval success rates. That's not because proteins in the brain are somehow unusual - we just aren't good at getting things to the brain. A company that focuses on genetically validated targets in the CNS and has delivery vehicles capable of crossing the blood-brain barrier has a lot of upside potential. Perhaps that's the reason AbbVie was willing to pay $1.4b in cash for a Phase 1 blood-brain crossing antibody from Aliada (a premium price for such an early asset).
[2] Not all. APOE4 / Genetic form of MASH - but most are still a small subset of a given disease. Also cardiovascular targets (PCSK9, ANGPTL3, APOC3)
Can the biggest biotech outcomes come from repurposed drugs?
"The most fruitful basis of the discovery of a new drug is to start with an old drug" — James Black (Nobel Laureate)
Perhaps you can refuse to spend any money on early R&D and safety studies, and instead weaponize ChatGPT to index all the possible mechanisms in all the possible diseases and drugs that can potentially target those. I've heard this pitch from at least 4 different friends in the past 3 months, so I suspect many people are pursuing this avenue now, or some other approach to repurposing.
It is a truly attractive idea – drug repurposing 'skips' the failure rates of initial stages of drug development (actual drug engineering and often Phase 1 trials) and focuses just on the risk of asset-disease match. With the failure rate from bench to Phase 1 being around 42.5 %, that's a significant upgrade to your chances of success. Repurposing gifted the world Viagra (redirected from angina to erectile dysfunction) and Minoxidil (from hypertension to baldness). As it often happens, these early big wins came from serendipity – clinicians just observed that minoxidil patients grow hair and Viagra patients don't want to return their pills – and not from any rational design. But how well have we done when approaching repurposing rationally?
There is surprisingly little data out there on how well intentional drug repurposing actually works. Estimates range from 30% to 75% success rate, which is a difference between 'it works no better than any other drug discovery' to 'drug repurposing will print you approval after approval'. It doesn't help that there is basically no definitive up-to-date list of all the drugs that were ever repurposed.
Definitions in drug repurposing are a sliding scale, too, including some papers classifying indication expansion as drug repurposing (it is not). How stringent you are with the terminology really matters, as it either makes repurposing look like an absolute success or a complete failure. For example, in 2020, one informal working group of 50+ drug developers could not "document a single instance of a drug approved for clinical use where the idea for the clinical trial derived first from a virtual or lab-based screen of old drugs." That is, taking old drug libraries and testing them in sufficiently new disease models yielded exactly 0 approved drugs.
But that's hypothesis-free repurposing. How about a more focused approach, where you start with a rationale and narrow the scope of possible treatments? That was also demonstrated during the COVID pandemic, with more than 300 drugs tested in a repurposing effort to treat COVID infections. Success rates were no better than anywhere else in the industry - a mere 1.6%, with 5 drugs out of 305 tested being repurposed for reducing mortality and shortening recovery in a subset of patients.
With 23,000 assets in the global clinical pipeline, 20,000 marketed Rx products, and more than 18,500 cataloged human diseases (~14,500 of which have no treatment), one would think there are many insights yet to be generated. That experiment has already been run by Recursion Tx. In the first 10 years of their operations and before they changed their strategy, Recursion built a pretty powerful engine with 1 million molecules screened and 150 indications explored. With $1.45 billion spent, Recursion had 7 programs that started Phase 1. 3 of those were repurposed. With only 1 repurposed program being active today.
Many point to Vivek's Roivant as a successful case for repurposing, but I am not truly convinced that they are a case study here either. Roivant has had tremendous success, no doubt. But they largely focused on 'flipping' developed assets, drugs deprioritized from pipelines, drugs that companies had no money to develop, and taking them to the next stage. They are driven by clinical or development insights, which, compared to scientific insights, tend to be less black-boxy and are much easier to milk high probabilities of success from.
My intuition is that insight-driven AI-powered repurposing will suffer from all the same troubles that traditional drug discovery suffers from. It will just do it in a slightly different style. You can swim in freestyle or backstroke, but that won't make you into an electric boat. Big one-off successes like Karuna's Cobenfy are still overshadowed by failures where the insight seemed like a no-brainer. It is also true for cases where literature and all the prior studies were giving a strong signal - e.g., early epidemiological studies showed that statin users have ~50% lower incidence of Alzheimer's, and yet the simvastatin trials in AD failed. And it's by far not the only such case. In a nutshell, repurposing occasionally yields cheap wins, but systematic attempts so far have performed no better than chance, making it unreliable as a foundation for billion-dollar pipelines.
Some big companies to build in drug repurposing:
- I think there is probably a place for a few more Roivants out there - companies that focus on business and indication risks, and have absolutely 0 tolerance for scientific risk (i.e., not trying to be creative with mechanistic insights, not relying on literature to make novel connections). With a record number of biotechs going bankrupt in this market, there are now many undervalued assets up for grabs.
[3] It is unclear whether Viagra is a true repurposing case since it never reached approval for its original indication
Will AI help us develop the next blockbusters?
In today's market, even companies with multiple approved drugs can trade below their cash balances. Given this, it is truly perplexing to see AI-biotechs raise mega-rounds at the preclinical stage - Xaira with a billion-dollar seed, Isomorphic with $600M, EvolutionaryScale with $142M, and InceptiveBio with $100M, to name a few. The scale and stage of these rounds reflect some investors' belief that AI-biology pairing can bend the drug discovery economics I described before.
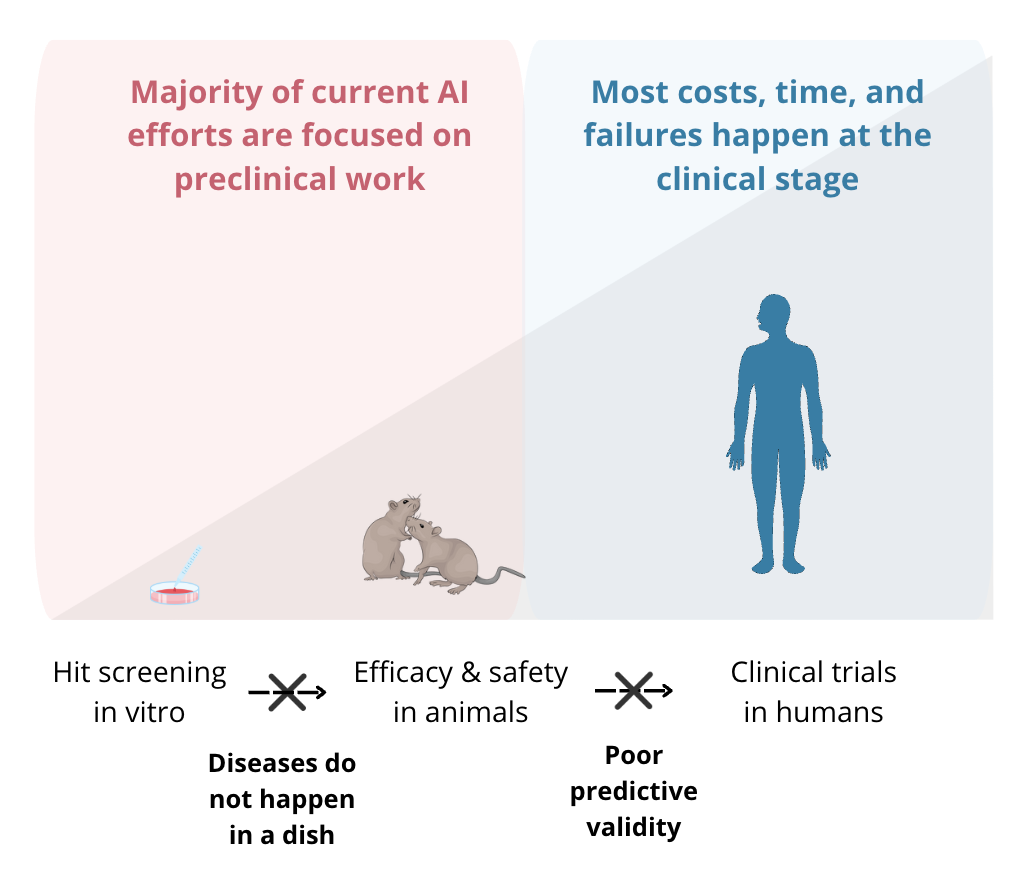
To me, the question of whether AI will be helpful in drug discovery is not as interesting as the question of whether AI can turn a 2-billion-dollar drug development into a 200-million-dollar drug development, or whether 10 years to approve a drug can become 5 years to approve a drug. AI will be used to assist drug discovery in the same way software has been used for decades, and, given enough time, we know it will change everything. But is "enough time" 3 years or half a century?
One number that is worth appreciating is that 80% of all costs associated with bringing a drug to market come from clinical-stage work. That is, if we ever get to molecules designed and preclinically validated in under 1 year, we'll be impacting only a small fraction of what makes drug discovery hard. This productivity gain cap is especially striking given that the majority of the data we can use to train models today is still preclinical, and, in most cases, even pre-animal. A perfect model predictive of in vitro tox saves you time on running in vitro tox (which is less than a few weeks anyway!), doesn't bridge the in vitro to animal translation gap, and especially does not affect the dreaded animal-to-human jump. As such, perfecting predictive validity for preclinical work is the current best-case scenario for the industry. Though we don't have a sufficient amount and types of data to solve even that.
It also makes me wonder about the kinds of data we should be using to find drugs for age-related diseases. There is technically no aging in in vitro cell models - aging is a phenomenon emergent on the organism level. Then, if we make it our goal to start generating high-throughput interventional datasets in vivo, what animal do we pick? Mice, the most accessible model for this, do not naturally develop Alzheimer's, Parkinson's, or lung fibrosis. Mice, unlike humans, do not die of heart attacks. It doesn't matter how many times you sequence them - the nodes in the system we should be intervening on are simply not conserved. Unfortunately, even cancer models, perhaps the most "conserved" complex disease between humans and mice, have poor predictive power for clinical readouts, with cancer drugs having the highest failure rate as a class overall. This has been an issue for brute force age-related disease drug development, and I suspect it will remain an issue if we were to cloak this process with AI.
| Therapeutic Area | P1 to P2 | P2 to P3 | P3 to Approval | Overall |
|---|---|---|---|---|
| Oncology | 57.6 | 32.7 | 35.5 | 3.4 |
| Metabolic/Endocrinology | 76.2 | 59.7 | 51.6 | 19.6 |
| Cardiovascular | 73.3 | 65.7 | 62.2 | 25.5 |
| Central Nervous System | 73.2 | 51.9 | 51.1 | 15.0 |
| Autoimmune/Inflammation | 69.8 | 45.7 | 63.7 | 15.1 |
| Genitourinary | 68.7 | 57.1 | 66.5 | 21.6 |
| Infectious Disease | 70.1 | 58.3 | 75.3 | 25.2 |
| Ophthalmology | 87.1 | 60.7 | 74.9 | 32.6 |
| Vaccines (Infectious Disease) | 76.8 | 58.2 | 85.4 | 33.4 |
| Overall | 66.4 | 48.6 | 59.0 | 13.8 |
| Overall (Excluding Oncology) | 73.0 | 55.7 | 63.6 | 20.9 |
Source: Chi Heem Wong, Kien Wei Siah, Andrew W Lo. Estimation of clinical trial success rates and related parameters. DOI: 10.1093/biostatistics/kxx069
I'd be willing to bet that many very hard AI-bio problems (maybe even virtual cells!) will be solved long before we can significantly (halve the costs type of significantly) impact drug development with AI. The jury is still out on whether the molecules designed by today's AI biotechs will be successful in trials. Although we know that the molecules designed by BenevolentAI or nominated by Recursion, the first gen of AI-for-bio companies, were not successful, it is probably too early to tell. For more recent incubations, we'd need to see Phase 2 readouts, because that's where fires burn the hottest (about half of drugs pass Phase 1 trials). This means that the real test won't arrive until well after 2027 for Isomorphic, and later still for Xaira - when the first definitive Phase 2 results will feed back as error signals into how we judge AI-biotech's promise.
I also think that new-gen biotechs using fine-tuned wrappers over publicly accessible agents won't be a separate company category since there is no biotech that I know of that isn't using agents for literature search, diligence, and cutting down on consulting costs. Unless you have access to large datasets of tacit knowledge that is never explicitly written anywhere (some companies are trying this now), it would be tough to make a case that wrappers will be significantly better than interacting with an agent. Overall, that AI can accelerate preclinical steps is an easy bet to make. However, since the overwhelming majority of time and costs lie in the clinic, its impact on biotech economics will remain marginal until we have a way to connect our preclinical insights to human efficacy.
Companies to build:
- I think being able to predict efficacy in humans is what will ultimately bend the painful economics of biotech. This is also the direction in which almost no progress is being made in the current AI/biotech landscape. Efficacy predictions would be the biggest and hardest problem to solve, but if we were to start somewhere, diseases conserved between humans and animal models would be it.
[4] Since the whole point of this essay is to focus on unfair advantages, I think it makes sense to ignore any productivity improvements that are evenly distributed, such as the FDA's adoption of AI-powered data management or review of regulatory submissions, which are all likely to occur soon.
There is only one way to increase the returns that drugs generate
When was the last time the industry managed to get the IRR number to go up? It wasn't better targets, it wasn't AI, and it wasn't cheap Chinese trials. Both in the case of the 2021 and 2024 industry comebacks, the average return on investment rose because of sales of drugs for extremely large patient populations - COVID vaccines and GLP-1s. To me, big indications almost always mean age-related indications, since aging is the only disease that affects everyone ("aging is the biggest TAM on Earth"). So if you asked me to write a recipe for an industry-wide fix, I would start with age-related diseases: Alzheimer's, sarcopenia, and heart disease. Solving those would almost certainly put pharma growth back on track. Yet in 2024, of the 50 new drugs approved, only 2 targeted age-related indications (Resmetirom and Donanemab). The same trend was true in all the previous years.
I generally don't subscribe to the idea that pharma isn't solving aging because their thinking is old-school or outdated. This ignores the fact that companies like Novartis, Regeneron, and Eli Lilly have long-standing "aging" research arms, and that many pharmas are experienced with multi-morbidity and all-cause mortality trials. If aging represents a trillion-dollar market, but the field still has little traction in addressing it, it's not because people with PhDs are blind to opportunities or complacent about the lack of progress. I've written about this before, but the reality is that, despite our best efforts and billions in investments, we just aren't very good at treating age-related diseases.
Our best heuristics for drug development are just failing to work here. First, genetic targets have poor propagation to late-stage damage. I think of genetic variants as models for early prevention. Unfortunately, factors that prevent late-stage disease are, in most cases, harmful to carry as a genetic variant in youth. For example, targets that ended up being successful for reducing fibrosis in age-related lung disease, IPF - like PDGFR, FGFR, and VEGFR - are essential for tissue repair, capillary growth, and connective tissue formation. This means our standard approach to discovering treatment targets is much harder to apply here.
In alternative approaches to target discovery, aging also breaks our intuition about cause and effect. We are used to the idea that, if something seemingly causes damage, then clearing it will fix the disease. In age-related macular degeneration, for instance, accumulation of complement proteins in extracellular retinal debris was one of the most consistent clinical features observed in patients. However, when complement cascade activation was pharmaceutically halted, there was no improvement in vision decline. Similarly, one of the most obvious features of Alzheimer's is amyloid plaques in post-mortem patient brains. Multiple drugs have now cleared plaques successfully, yet they show no evidence of improved cognition. In fact, most beta-amyloid drugs shrink patients' brains. Multidimensional problems, of course, require multidimensional solutions, and perhaps AI will eventually help us resolve some of these mysteries. Though, as I mentioned, most of the data collection does not focus on these aspects for now. And very little of it is human-derived.
Reading and identifying the right signals is half of the issue. Having tools to target those signals is another half. One useful example to think about is exercise, which is one of the few interventions that is documented to extend lifespan in humans and delay the onset of multiple age-related diseases. Many companies worked on identifying exercise mimetics - taking proteins or molecules secreted in the exercise and developing them into cardiometabolic drugs. This approach has been quite successful, yielding FGF21 as a treatment for age-related liver disease, MASH. At the same time, we know that targeting 1 pathway and potently increasing muscle mass didn't improve muscle function in old sarcopenic adults, let alone extend their lifespan. There are hundreds of proteins secreted during exercise, and we currently have no therapeutic modalities that work like that. At most, we can go through a painful co-formulation process and put a few of those into one syringe - and that's if we are lucky. Thus, any technologies that can write complexity in the right organ at the right time would be a big step change for future aging treatments.
I also wanted to list some companies within the aging space that are worth building. For the list below, I mostly have a 10-year horizon in mind. I do hope that on a 20 to 100-year timescale, we'll be doing things that are more ambitious than the ones I list here:
Loyal for humans or creating a regulatory path to approving drugs for human aging broadly - likely to be done with existing approved / safe molecules and modalities
Targeted organ delivery. I like jokingly saying that "there is no such thing as aging", but only because aging is not one thing we can point to - it looks extremely different across different organs. Some mechanisms for aging prevention might be systemic, but when it comes to targeting damage, it would almost certainly have to be targeted to 1 organ at a time. Many people are working on targeted delivery, but almost no one is pursuing targeted delivery to aged organs. Since many of the receptors conventionally used for ligand/peptide-based targeting of LNPs / AAVs can be downregulated in aging, this leaves a pretty big gap in current delivery tech.
Broadly, more ambitious therapeutic modalities that would unlock our ability to target new types of damage and complexity at a molecular level. Cell programming, epigenetic editing, RNA editing, extracellular protein degraders, in vivo CAR-Ts, proximity chimeras to install PTMs... Most of these things didn't exist 10-15 years ago, and are still in early development today. I think new tools would be big multipliers of the progress in our ability to treat aging
Closing thoughts
Drug development, like any other industry, is greedy - it addresses the most tractable diseases with the biggest outcomes first. Genetic targets, clear biomarkers, and one-pathway wins gave rise to the biotech boom of the 70s and 90s, when recombinant insulin, monoclonal antibodies, and early gene therapies created a sense of an endless frontier. Unlike with other industries, reinvesting capital from those early wins back into the ecosystem didn't accelerate industry's progress – we've been on a reverse trend for a while now. Today, remaining problems resist the very playbook this industry was built on.
Most industries have eras when progress stalls before a new paradigm unlocks scale again. Electricity needed transmission grids, computers needed operating systems, and aviation needed jet engines. For biotech, whether the shift will come from new modalities, new regulatory frameworks, or entirely new ways to validate efficacy in humans is not yet clear, but we can, perhaps, outline the boundaries within which that future will exist: manufacturing and trials should get cheaper with each run, regulations should become more adaptive, approval frameworks should increase and not decrease in variance, and new therapeutic modalities should focus on unlocking new biology, not just producing slightly better iterations on problems we already know how to solve. Until those new paradigms take hold, building a trillion-dollar biotech will remain caught in Lewis Carroll's logic: running as fast as we can just to stay in place, and twice as fast to make any real progress.
Huge thanks to Dwarkesh Patel, Alex Telford, Erik Torenberg, and Laksh Aithani for commenting on (and arguing with me about) the many drafts of this essay.